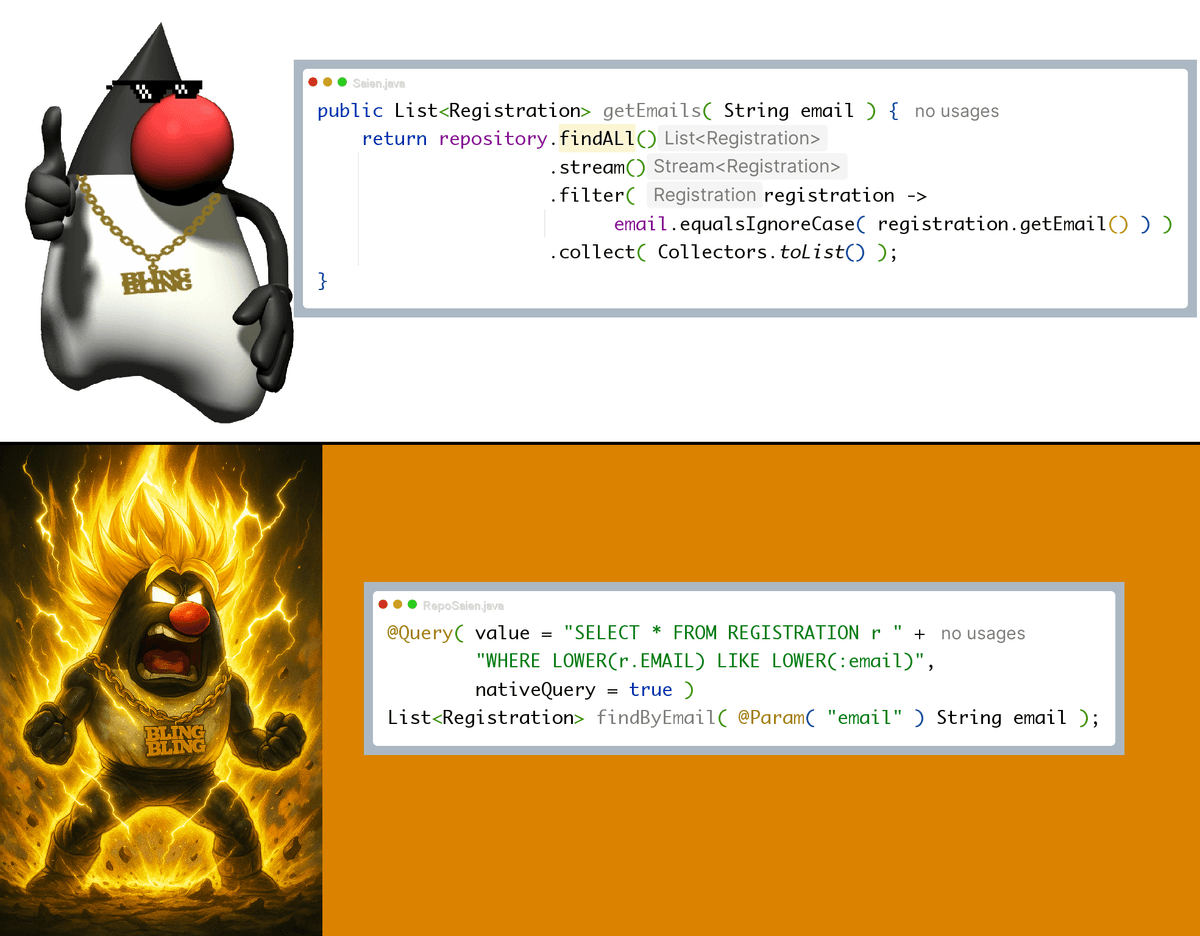
Ever seen this pattern?
public List<Registration> getEmails(String email) { return repository.findAll() .stream() .filter(r -> email.equalsIgnoreCase(r.getEmail())) .collect(Collectors.toList()); }
It “works”… until it doesn’t. Pulling every row to the app and filtering in memory is a silent performance killer.
A safer, faster approach is to let the database do the work:
@Query( value = """ SELECT * FROM REGISTRATION r WHERE LOWER(r.EMAIL) LIKE LOWER(:email) """, nativeQuery = true ) List<Registration> findByEmail(@Param("email") String email);
Why the query wins 🏆
Performance & scalability: Filtering happens server-side. You transfer only matching rows over the network and avoid loading the entire table into JVM memory.
Indexes: The DB can leverage indexes for fast lookups. In-memory filtering can’t.
Correctness: Case-insensitive matching and SQL semantics (LIKE/ILIKE, collations) are consistent and locale-aware; equalsIgnoreCase() isn’t.
Security: Parameters are bound, preventing SQL injection.
Observability: DB plans are explainable and optimizable; streams hide the cost until prod traffic hits.
Transactions: Reads participate in DB isolation levels; client-side filters don’t.
Make it even better ✅
Prefer Spring Data method names when possible:
If you’re on PostgreSQL, use ILIKE (case-insensitive) or CITEXT for index-friendly case-insensitive equality:
Avoid LOWER(column) unless you have a functional index—it can block index usage. Prefer ILIKE/collations or a functional index:
Don’t SELECT * in production—choose explicit columns.
If email is unique, return Optional and enforce a unique constraint on the column.
TL;DR 🎯
Filtering in Java wastes CPU, memory, and bandwidth. Push filters to the database for correctness and speed, and lean on Spring Data’s derived queries or DB-native features for clean, maintainable code.
#java #springboot #springdata #jpa #performance #database #postgresql #cleanarchitecture #scalability
Go further with Java certification:
Java👇
Spring👇